Haowen Shi
Computer engineering and robotics enthusiast.
Parallel LiDAR Depth Image Renderer
Parallel implementation of a renderer projecting 3D LiDAR points to 2D image.

This project is done as our class project for CMU 15-418 Parallel Computer Architecture and Programming.
Authors
- Henry Zhang (hengruiz@andrew.cmu.edu)
- Haowen Shi (haowensh@andrew.cmu.edu)
Abstract
In this project we implemented a LiDAR depth image rendering too which takes in LiDAR 3D point clouds in the world frame and renders a depth image from the camera’s field of view by transforming and projecting these points.
We implemented sequential (one process on single CPU core), OpenMP, and CUDA versions, then benchmarked and compared their performance.
Framework
OpenMP
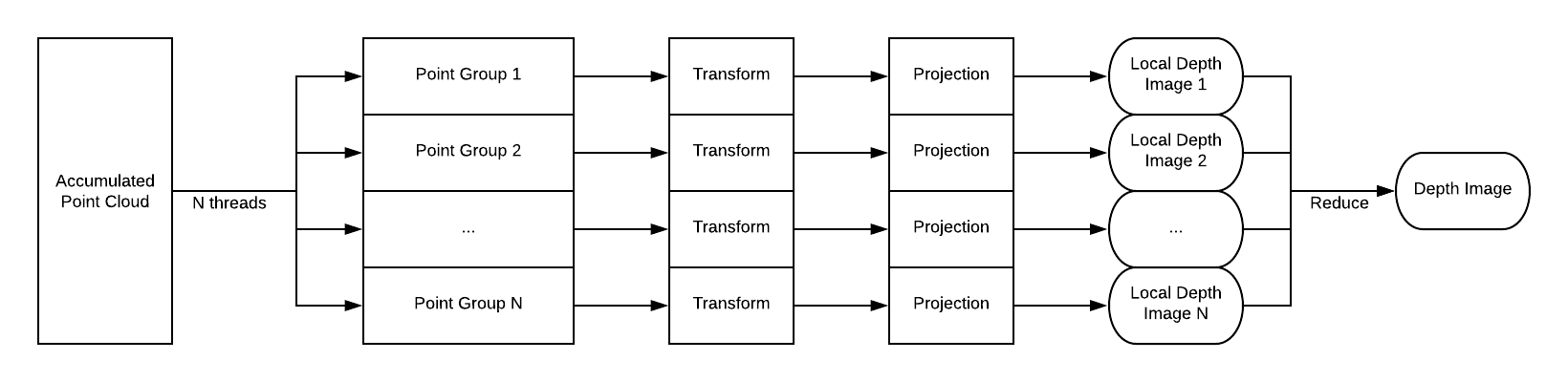
In this implementation, we group up the incoming lidar points and distribute them evenly across number of designated cores.
CUDA
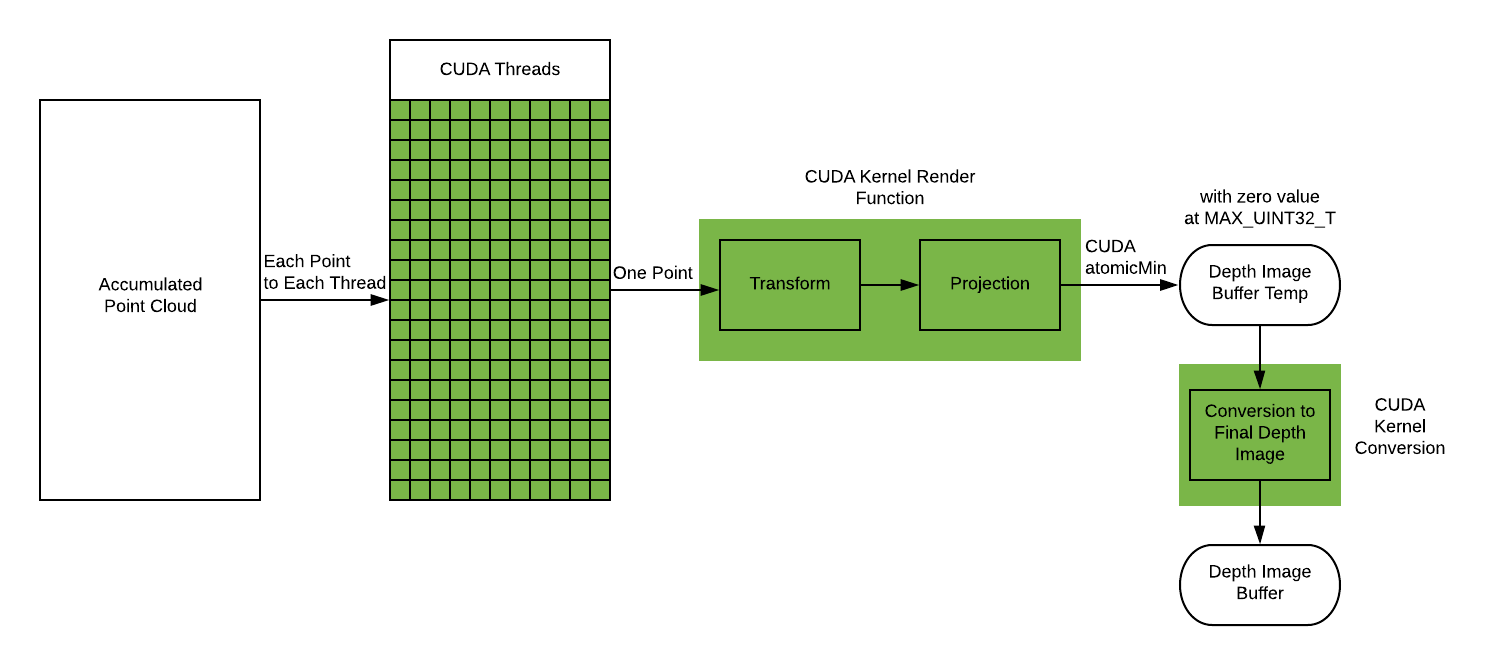
In this implementation, we have the same workload splitting strategy but spread them across many more GPU compute cores. Because we could not use the PCL library on CUDA code, we designed custom data wrappers for low-overhead communication between CPU and GPU and implemented some PCL pcocessing code ourselves.
Results
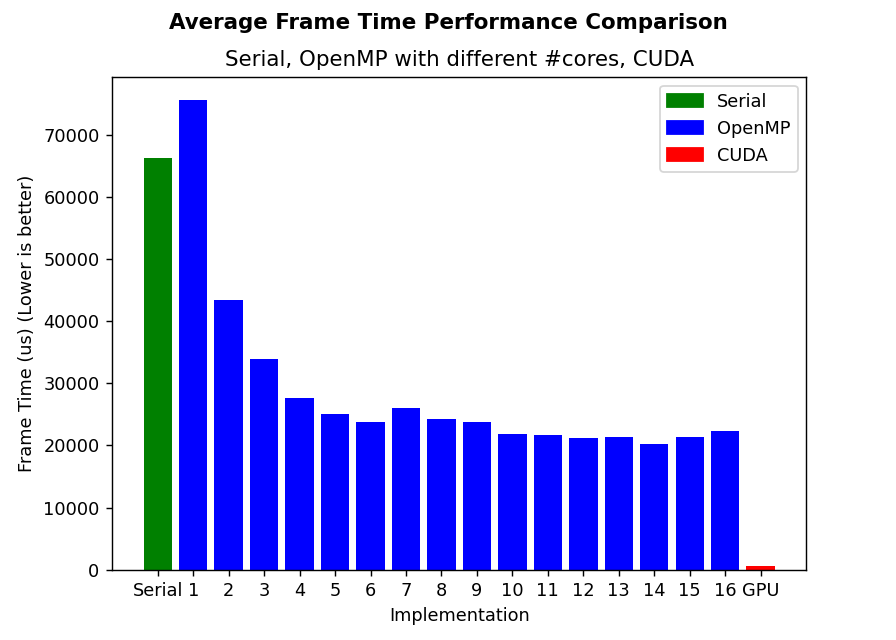

For the same dataset with constant high workload for the renderer, We achieved on average, maximum of 2.9x speedup for OpenMP implementation and 120x speedup for CUDA implementation.
tags: CUDA | OpenMP | performance-engineering | PCL | ROS